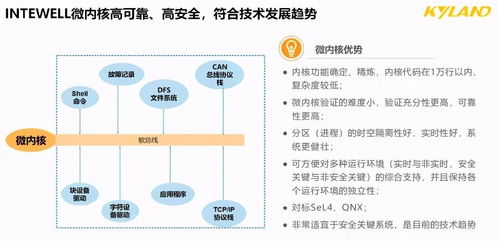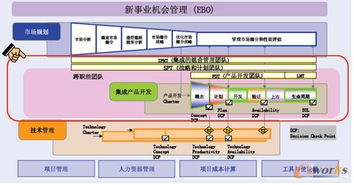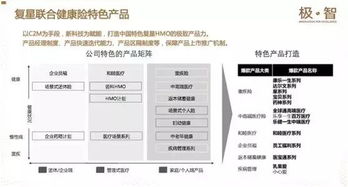
隨著國家對(duì)安全生產(chǎn)監(jiān)管的不斷加強(qiáng),生產(chǎn)加工型小微企業(yè)亟需提升安全管理水平。本培訓(xùn)課程旨在幫助安全管理人員系統(tǒng)掌握核心業(yè)務(wù)能力,內(nèi)容涵蓋安全生產(chǎn)管理、消防安全管理、事故應(yīng)急處置及案例分析等關(guān)鍵領(lǐng)域。
一、安全生產(chǎn)管理
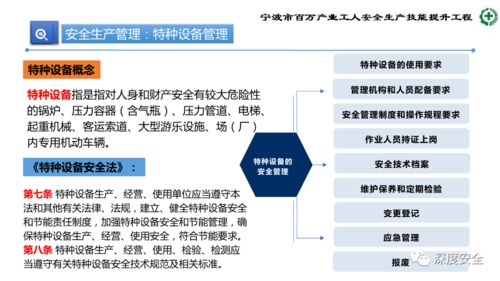
安全生產(chǎn)是企業(yè)發(fā)展的生命線。小微企業(yè)應(yīng)建立完善的安全生產(chǎn)責(zé)任制,明確各級(jí)管理人員職責(zé)。重點(diǎn)包括:1. 制定安全生產(chǎn)規(guī)章制度和操作規(guī)程;2. 定期開展風(fēng)險(xiǎn)評(píng)估和隱患排查;3. 加強(qiáng)設(shè)備維護(hù)保養(yǎng)和作業(yè)環(huán)境管理;4. 實(shí)施員工安全教育培訓(xùn),提高全員安全意識(shí)。通過標(biāo)準(zhǔn)化管理,有效預(yù)防生產(chǎn)安全事故的發(fā)生。
二、消防安全管理
消防安全是安全生產(chǎn)的重要組成部分。小微企業(yè)需重點(diǎn)關(guān)注:1. 合理配置消防設(shè)施,如滅火器、疏散指示標(biāo)志等,并定期檢查維護(hù);2. 嚴(yán)格管理易燃易爆物品,規(guī)范存儲(chǔ)和使用流程;3. 制定消防應(yīng)急預(yù)案,定期組織演練;4. 加強(qiáng)電氣線路和用火管理,杜絕火災(zāi)隱患。只有將消防措施落到實(shí)處,才能保障企業(yè)財(cái)產(chǎn)和員工生命安全。
三、事故應(yīng)急處置
事故應(yīng)急處置能力直接關(guān)系到事故后果的嚴(yán)重程度。企業(yè)應(yīng)建立健全應(yīng)急機(jī)制:1. 制定科學(xué)、實(shí)用的應(yīng)急預(yù)案,明確響應(yīng)流程和職責(zé)分工;2. 配備必要的應(yīng)急物資和設(shè)備;3. 定期開展應(yīng)急演練,提升員工自救互救能力;4. 事故發(fā)生后,迅速啟動(dòng)應(yīng)急程序,控制事態(tài)發(fā)展,并按規(guī)定報(bào)告。快速、有效的應(yīng)急處置能夠最大限度地減少損失。
四、案例分析
通過真實(shí)案例剖析,加深對(duì)安全管理重要性的認(rèn)識(shí)。例如:某小微加工企業(yè)因未定期檢查設(shè)備,導(dǎo)致機(jī)械故障引發(fā)傷害事故;另一企業(yè)因消防通道堵塞,在火災(zāi)中造成人員傷亡。這些案例警示我們:麻痹大意是安全的大敵。企業(yè)必須引以為戒,舉一反三,不斷完善安全管理措施。
五、企業(yè)管理與安全文化
安全管理不僅是技術(shù)問題,更是管理問題。小微企業(yè)應(yīng)將安全納入企業(yè)戰(zhàn)略,推動(dòng)安全文化建設(shè):1. 領(lǐng)導(dǎo)者率先垂范,重視安全投入;2. 建立激勵(lì)機(jī)制,鼓勵(lì)員工參與安全管理;3. 持續(xù)改進(jìn),定期評(píng)審安全管理體系的有效性。唯有將安全理念融入企業(yè)管理每個(gè)環(huán)節(jié),才能實(shí)現(xiàn)長治久安。
生產(chǎn)加工型小微企業(yè)安全管理人員必須全面掌握上述業(yè)務(wù)能力,通過系統(tǒng)培訓(xùn)和持續(xù)實(shí)踐,為企業(yè)筑牢安全防線,助力企業(yè)健康可持續(xù)發(fā)展。