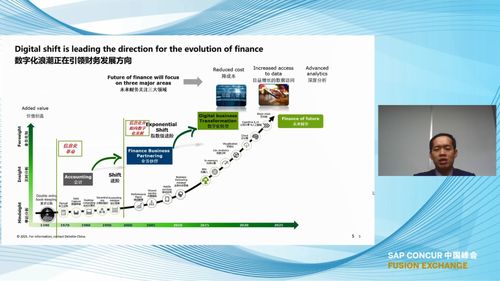
在近日舉行的 SAP Concur 中國峰會上,來自各行業的企業管理精英與專家齊聚一堂,共同探討數字化時代下的企業管理新趨勢與實踐。峰會聚焦財務自動化、差旅費用管理及數據驅動決策等核心議題,為與會者帶來豐富的洞見與啟發。以下為峰會中的精彩金句集錦,旨在為企業在管理優化與數字化轉型中提供參考。
1. 關于數字化轉型:
‘數字化不是選項,而是企業生存與發展的必然路徑。SAP Concur 助力企業將繁瑣流程轉化為智能洞察,讓數據說話,讓管理更高效。’
2. 關于費用與差旅管理:
‘智能費用管理不僅僅是節省成本,更是提升員工體驗與合規性的關鍵。通過自動化,企業能將資源專注于創新,而非瑣碎事務。’
3. 關于數據驅動決策:
‘在信息爆炸的時代,優質的數據是企業最寶貴的資產。SAP Concur 提供的實時分析,讓管理者從‘后視鏡’視角轉向‘導航儀’模式,預見風險、把握機遇。’
4. 關于團隊與領導力:
‘偉大的企業管理源于對細節的關注與對人員的賦能。借助工具如 Concur,領導者可以更專注于戰略制定,而非日常審批,從而激發團隊潛能。’
5. 關于全球化與本地化:
‘在中國市場,企業需平衡全球化標準與本地化需求。SAP Concur 的靈活解決方案,幫助企業在合規基礎上實現無縫擴張,連接世界與本土。’
這些金句不僅總結了峰會的核心思想,也反映了當前企業管理的前沿動態。通過采納智能工具與數據驅動方法,企業可以提升運營效率、增強競爭力,并在不確定的經濟環境中穩健前行。SAP Concur 中國峰會為行業交流搭建了寶貴平臺,我們期待未來更多合作與創新,共同推動企業管理邁向新高度。